Analiza danych z pomocą AI: testujemy ChatGPT, Claude’a i inne modele językowe
Jeśli używasz ChatGPT do edycji tekstu i rozwiązywania codziennych problemów, dlaczego nie miałbyś zlecić mu analizy danych z bazy czy arkusza kalkulacyjnego? Zobacz, jak duże modele językowe (LLM) radzą sobie z przetwarzaniem tabel i jak możesz je wykorzystać w swoich projektach.
Karol PiekarskiWarsztaty
Poniższe wskazówki spisaliśmy na podstawie doświadczeń ze spotkania w Medialabie. Wzięliśmy na warsztat kilka modeli ❶ i zleciliśmy im analizę próbek danych z badań ankietowych ❷. Artykuł nie zagłębia się w zawiłości samej analizy danych – pokazuje natomiast, jak można ją usprawnić dzięki AI ❸.
Który model wybrać do pracy z danymi?
Nie będziemy wyrokować, który model jest najlepszy w analizie danych. Pokażemy natomiast, czego unikać i jak sprawdzić, czy wybrany asystent rzeczywiście poradzi sobie z zadaniem. Pamiętaj: duże modele językowe specjalizują się w przetwarzaniu języka naturalnego, niekoniecznie w operacjach matematycznych.
Czasem do obliczeń bardziej przyda ci się zwykły arkusz niż wyrafinowane sieci neuronowe.
Załóżmy jednak, że chcesz powierzyć zadanie analityczne modelowi, licząc na jego pomoc w interpretacji wyników czy wyborze najlepszej metody badań. Nic nie stoi na przeszkodzie, by dać mu dostęp do sprawdzonych narzędzi analitycznych. To właśnie robią tak zwane tool calls. Gdy poprosisz model o wykonanie obliczeń, powinien sięgnąć do jednego z takich narzędzi (np. języka Python), które wykona zadanie za ciebie. Zobacz poniżej, jak Claude informuje nas o instalacji odpowiedniej biblioteki i wczytywaniu bazy danych.
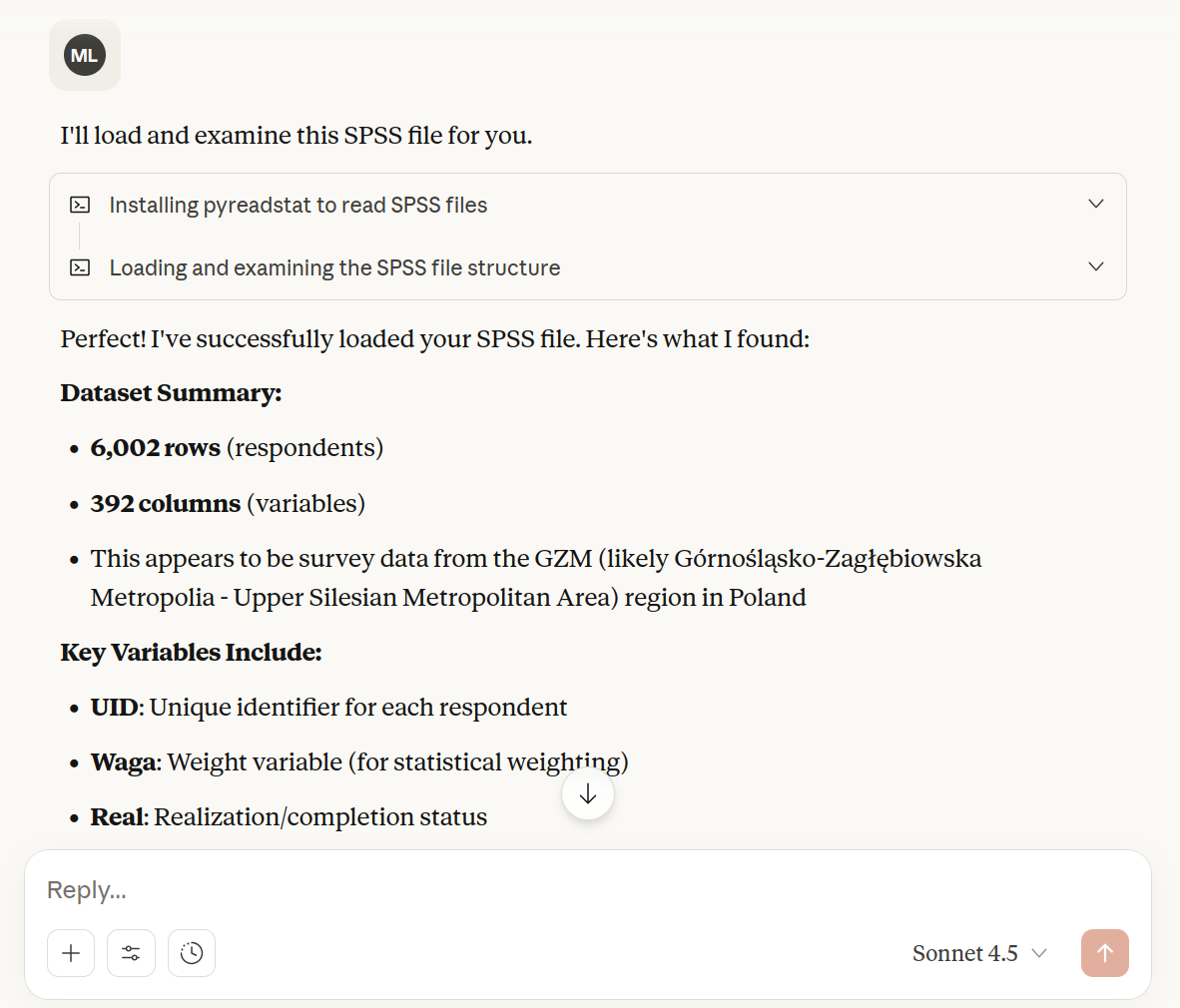
Twoje pierwsze zadanie w pracy z modelem? Upewnij się, że ma dostęp do odpowiednich funkcji. Po prostu zapytaj wprost, czy użył ich do wykonania obliczeń i w jaki sposób to zrobił. Obserwuj też status wykonania – zobaczysz na przykład, gdy asystent uruchamia środowisko Python. Nie martw się, nie musisz znać tego języka, by to zauważyć. Zadawanie pytań wyjaśniających to najlepszy sposób, by potwierdzić poprawne wykorzystanie dostępnych możliwości (choć nie wszystkie modele podzielą się taką informacją).
Import danych – tu zaczynają się schody
Najbardziej intrygujący wniosek z naszych warsztatów? Modele najczęściej popełniają błędy już na samym początku, podczas importu danych. To paradoks, ale nawet najwyższej klasy narzędziom (ChatGPT, Claude i Qwen) zdarzały się pomyłki podczas wgrywania niewielkich zbiorów danych. Dlatego zawsze upewnij się, choćby manualnie porównując liczbę wgranych wierszy z oryginalnym plikiem, że wszystko jest w porządku.
Przeanalizuj ten plik CSV i powiedz mi:
(1) ile ma wierszy i kolumn,
(2) co reprezentuje każda kolumna,
(3) jakie typy danych są w każdej kolumnie oraz
(4) czy są jakieś brakujące wartości lub oczywiste problemy z jakością danych.Choć obecne narzędzia mają coraz większe możliwości – np. Claude potrafi wczytać bazę danych SPSS czy doinstalować brakujące biblioteki analityczne – warto ułatwić im zadanie. Korzystaj z najbardziej popularnych i uniwersalnych formatów, takich jak CSV. Jeśli to nie problem, wyeksportuj swój arkusz kalkulacyjny do tego formatu, zanim wrzucisz go do modelu. Proste rozwiązania działają najlepiej.
Jak poprowadzić analizę krok po kroku?
Masz już przygotowane dane i pomysły badawcze – co dalej? Jeśli nie masz dużego doświadczenia w analizie danych, zawsze możesz poprosić model o wskazówki. Zadaj takie pytanie:
Mam zbiór danych dotyczący [temat badania].
Chcę zbadać [cel analizy], ale nie mam doświadczenia w analizie danych.
Czy możesz zaproponować mi plan analizy krok po kroku? Opisz, jakie metody powinienem zastosować, w jakiej kolejności i dlaczego.Lub bardziej szczegółowa wersja:
Przeprowadź eksploracyjną analizę danych (EDA) tego zbioru.
Chcę poznać:
1) Podstawowe statystyki dla każdej zmiennej
2) Rozkłady wartości i potencjalne wartości odstające
3) Korelacje między zmiennymi
4) Brakujące dane i ich wzorce
5) Nietypowe obserwacje, które mogą wymagać uwagi
Przedstaw wyniki w przystępny sposób z wizualizacjami.Zapisz sobie najważniejsze wnioski z takiej eksploracji i dołącz je do instrukcji kolejnego prompta zawierającego docelowe pytania badawcze. To jak rozpoznanie terenu przed właściwą wyprawą: wiesz już, czego się spodziewać i gdzie mogą czaić się pułapki.
Nie ufaj ślepo – weryfikuj wszystko
I jeszcze jedno – nigdy nie zakładaj, że coś jest oczywiste. Modele językowe nie wykonają automatycznie czyszczenia czy weryfikacji danych (czasami to zrobią, czasem nie). Zawsze upewnij się, że powstał szczegółowy plan działania z instrukcjami krok po kroku. Im bardziej precyzyjny, tym lepiej.
Zarówno te plany, jak i finalne wyniki analiz warto wrzucić do innego modelu językowego pełniącego funkcję code review. Brzmi jak przesada? Niekoniecznie.
Wyobraź sobie taką sytuację: ChatGPT przeprowadza dla ciebie analizę satysfakcji klientów z ankiety. Wszystko wygląda świetnie: ładne wykresy, przekonujące wnioski. Ale czy na pewno model poprawnie obsłużył brakujące dane? Czy nie pominął istotnych zmiennych?
Weź te same dane i kod analizy, a następnie przekaż je do Claude’a, Gemini lub innego modelu z takim zapytaniem:
Sprawdź poniższą analizę danych pod kątem:
1. Błędów metodologicznych – czy zastosowane metody są właściwe?
2. Jakości kodu – czy nie ma oczywistych błędów w obliczeniach?
3. Obsługi brakujących danych – czy zostały poprawnie potraktowane?
4. Wartości odstających – czy zostały zidentyfikowane i odpowiednio obsłużone?
5. Poprawności interpretacji wyników
Na co powinienem szczególnie zwrócić uwagę? Czy widzisz jakieś potencjalne problemy, które mogły być przeoczone?Drugi model może wychwycić rzeczy, których pierwszy przegapił – na przykład to, że wiersze bez odpowiedzi ankietowanych nie zostały poprawnie odfiltrowane przed analizą, zniekształcając dalsze pomiary.
To nie jest paranoja, lecz rozsądna ostrożność. Różne modele mogą w konkretnych przypadkach dać różne wyniki. Jeden lepiej poradzi sobie z twoim zestawem danych, drugi wychwycił coś, co pierwszy pominął. Wykorzystaj to na swoją korzyść, tworząc prosty system wzajemnej kontroli.
Rozwiązanie to nie da ci gwarancji, ale dostarczy kolejną warstwę bezpieczeństwa, która może uchronić cię przed kosztownymi pomyłkami. Pamiętaj – to my, a nie modele językowe, jesteśmy ostatecznie odpowiedzialni za wyniki ich analiz.
❶ Testowaliśmy następujące narzędzia: ChatGPT: Data Analyst, Claude Sonnet 4.5, Gemini 2.5 Pro, Qwen3 Coder.
❷ Nie prowadziliśmy systematycznych i rygorystycznych analiz, przedstawiamy wyłącznie refleksje z warsztatów bazujące na pojedyńczych doświadczeniach.
❸ Pełny przegląd zastosowań LLM-ów w analizie danych znajdziesz tutaj.
❹ Osobnym wyzwaniem jest wielkość zbioru danych. Nawet niewielki dataset szybko zapełni okno kontekstowe modelu językowego – tego rodzaju ograniczenia omówimy w kolejnym artykule.